
TalTechi kõnetöötluse kaasprofessor ja keeletehnoloogia labori juht

TalTechis arendatud kõnetõlkesüsteem tõlgib eestikeelset kõnet peaaegu reaalajas võõrkeelseks tekstiks, aidates seminaridel, konverentsidel ja avalikel aruteludel jõuda ka nende kuulajateni, kes eesti keelt ei mõista.
Pole sugugi haruldane, et Eestis toimuvate seminaride, konverentside ja Arvamusfestivali-suguste avalike arutelude auditooriumidest leiab üha sagedamini inimesi, kellel on raskusi eesti keele mõistmisega. Eestlastel on sellistel juhtudel kombeks minna üle inglise keelele, samuti kasutavad sündmuste korraldajad professionaalseid tõlke.
TalTechis on aga nüüd arendatud välja kõnetõlkesüsteem, mis pakub probleemile tehnoloogilise lahenduse: see tõlgib peaaegu sünkroonselt eestikeelse kõne teise keelde ja teisendab selle jooksvalt kirjalikuks tekstiks. TalTechi kõnetõlkesüsteem on tasuta kasutamiseks kõigile kättesaadav.
Kõnetõlkesüsteemiga ei taheta muidugi mõista asendada professionaalseid tõlke, kel tuleb vahendada täpsust ja nüansitundlikkust eeldavaid sõnavõtte. Samas võimaldab uus kõnetõlge laiendada eestikeelsete ettekannete ja arutelude vahetut kandepinda – see annab võimaluse jälgida väliskülalistel või rahvusvahelistel tudengitel ettekandeid ingliskeelsete subtiitrite abil.
Samuti saab kasutada tõlkevõimalust telefonekraani kaudu veebiseminaridel. Olgu lisatud, et süsteemi on jõutud juba erinevatel sündmustel edukalt katsetada.
Kuidas süsteem töötab?
Lahendus koosneb kahest osast: kõigepealt teisendab süsteem automaatse kõnetuvastuse abil eestikeelse jutu tekstiks, misjärel saadetakse tekst väikeste osade kaupa tõlkemudelile, et too saaks pakkuda välja algse kõne võõrkeelse tõlke. Süsteem kasutab minimalistlikku, kahe tekstikastiga kasutajaliidest: esimesse kasti ilmub eestikeelne tõlketuvastuse tekst, teise kasti aga tõlge.
On oluline, et süsteem ei jääks ootama tõlgitava lause lõppu – kõneleja sõnad ilmuvad ükshaaval lähtekeele kasti. Kui sõnu on kogunenud kindel arv (näiteks neli), saadetakse sõnade plokk tõlkemudelile, mis vastab võõrkeelsesse aknasse ilmuva osalise tõlkega. Nii tekitakse mulje tõlke sünkroonsusest, olgugi et tõlge teostub väikese viivitusega. Samas on tähtis, et süsteem ei hakkaks kord juba tõlgitud ja väljastatud sõnu ekraanil enam muutma, kuna sel juhul oleks tõlget üsna keeruline jälgida.
Teatud mööndustega võib lahendust nimetada sünkroonseks kõnetõlkeks. Mõne sekundi pikkune viivitus on vajalik või isegi paratamatu, sest tõlge pole ju enamasti sõnasõnaline, vaid vajab konkreetse fraasi – näiteks mõne fraseologismi – korrektseks vahendamiseks ümbritsevaid sõnu. Samas on viivitus piisavalt väike, et see ei takistaks kuulajal kõne kulgu vahetult jälgida.
Lõigud vs plokid
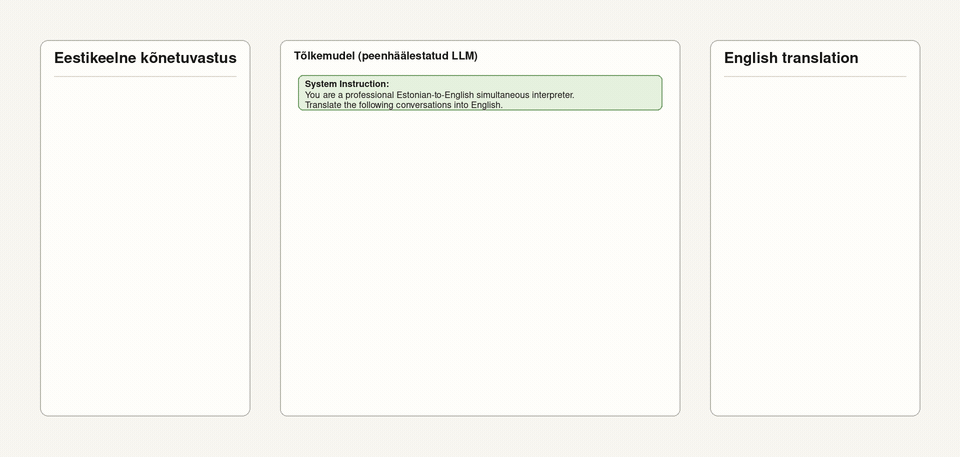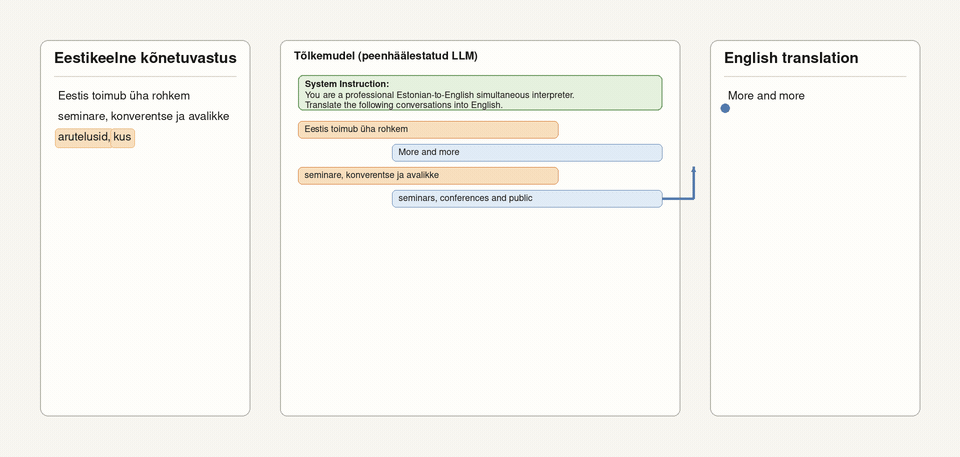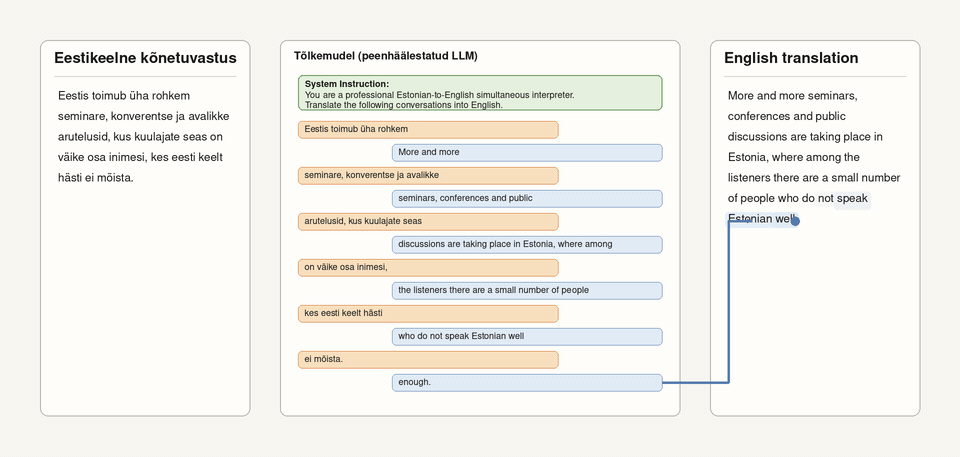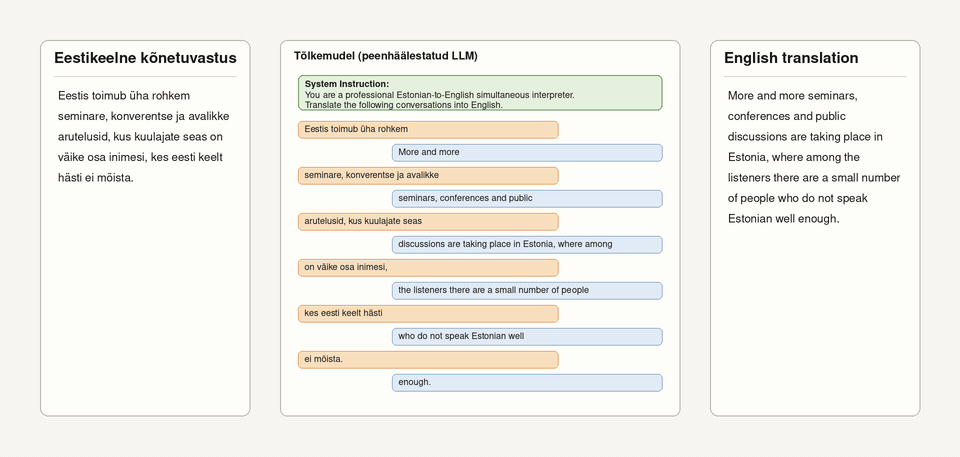
Tavaline masintõlge töötab üldjoontes lause- või lõigukaupa. Sünkroontõlkes ei saa sellist lähenemist kasutada, kuna kõneleja lause võib kesta päris kaua. Seetõttu kasutab meie süsteem tõlkimisel väikeseid sõnaplokke. Animatsioonil nähtavas näites võib jälgida, kuidas sisendlause algab sõnadega „Eestis on aina rohkem“, millele tõlkemudel vastab väljendiga „More and more“, s.t see jätab „Eesti“ tõlkimata.
Kui saabuvad aga järgmised sõnad – „seminare, konverentse ja avalikke“, võtab mudel uut tõlkeosa lisamisel arvesse ka varasemat kõneteksti. Sel kombel ilmub tõlgitud tekst ekraanile järk-järgult, mitte lausehaaval.
TalTechi kõnetõlkesüsteem teisendab eestikeelse kõne esmalt tekstiks ning vahendab selle seejärel peaaegu reaalajas ingliskeelse tõlkena.
Tõlkemudel ei tööta iga plokiga eraldi, vaid hoiab kõike eelnevat meeles. Võib öelda, et süsteem käsitleb tõlkimist omamoodi vestlusena: kõneleja suunalt saabub mudelisse järjepanu eestikeelseid lõike, millele mudel vastab võõrkeelsete lõikudega – seda enam, et tõlkemudel ei tegele mitte ainult parasjagu vahendamist vajavate sõnadega, vaid ühtlasi näeb ja tõlgendab see varasemaidki vestlusosi, et kergendada jooksvat tõlkeprotsessi. Selline interaktsioon aitab säilitada mõtte järjepidevust ning kasutada samu või sarnaseid väljendeid ühtlasemalt.
Samuti lähtub meie uus tõlkemudel mitte ainult tekstist, vaid ka kontekstist, jälgides kõneakti kaudu tekkivaid kontekstilisi võimalusi ja piiranguid. Tihti on tõlkeks saadetud sõnade vahendamiseks vaja oodata tulevasi sõnu.
Mõnikord võib juhtuda, et kui tõlkemudel näeb lause esimest plokki, ei pruugi ta anda vasteks ühtegi sõna või siis väljastab see vasteks väga lühikese tõlke. Kui saabub järgmine eestikeelne plokk, lisab mudel tõlke järgmise osa, millele võib omakorda lisanduda suuri osi äsja tõlkimata jäänud sisendtekstist.
Tõlkimise intervallid ja tasakaalupunktid
Sünkroontõlke puhul väljendubki keskne probleem küsimuses, millal tõlkida ja millal oodata järgmisi sõnu. Inimtõlk kasutab sama lähenemist, s.t ta võib selleks, et saada paremini aru, millises suunas kõneleja jutt liikuma hakkab, paari sõna võrra oodata – ootamise aeg sõltub tõlgitava lause ülesehitusest.
Sama põhimõtet püütakse õpetada tõlkemudelile. „Ootamist“ tutvustatakse mudelile näidetega, mille puhul on lähte- ja sihtkeelsed laused jagatud väikesteks joondatud juppideks, nii et iga tõlkesõna ilmub nähtavale alles siis, kui selleks vajalik lähtekeelne osa on juba esil.
Tehniline joondamine lähtub keelte paratamatutest erisustest, mis puudutavad alati ka süntaksit. Joondamise harjutamiseks võrreldakse eestikeelset lauset ja selle võõrkeelset tõlget ning leitakse teineteisele vastavad sõnad – nii on võimalik hinnata, millise lähtekeelse sõnani peab süsteem vastava tõlkesõna väljastamiseks jõudma. Seejärel ehitab süsteem lausete toel üles justkui väikese vestluse.
Taoline treening suurendab mudeli kontekstitaju – see õpib jäljendama mustrit, mis suunab väljastama tõlkeosa alles pärast piisava lähtekonteksti tekkimist. Kui treeningandmetes on hilisemast sõnast sõltuv tõlkeosa edasi lükatud, õpib mudel sellise näite põhjal ootama ning suurendama samas ka ootamise dünaamilisust: mõnes kohas on parem anda edasi täielik tõlge, teises kohas aga on targem jätta suur osa lähtekeele sõnadest mällu ja edastada nende jaoks tõlge alles mõnes hilisemas plokis.
Sünkroontõlke puhul on väga oluline leida ootamise ja tegutsemise vaheline tasakaal: süsteem ei tohi liiga kaua vaikida, et kuulaja tähelepanu ei saaks häiritud, ent see ei tohi ka liiga vara ja liiga palju oletada, sest kiirustamine võib kahjustada tõlkekvaliteeti – sama oht kipub varitsema tõlkivaid inimesi. Hoolikalt koostatud treeningandmed aitavad mudelil seda tasakaalu saavutada ja hoida.
Sünkroontõlke puhul on väga oluline leida ootamise ja tegutsemise vaheline tasakaal.

Tanel Alumäe sõnul võimaldab TalTechi kõnetõlkesüsteem eestikeelsetel kõnelejatel jääda oma emakeelele truuks ka rahvusvahelise kuulajaskonna ees. Foto: TalTech
Kasutaja pilk
Kasutaja jaoks on süsteem väga lihtne. Ekraanil on kaks tekstikasti. Vasakusse kasti kuvatakse kõnetuvastuse tulemus – see, mida süsteem arvab olevat kõnelejat eesti keeles öelnud. Parempoolses kastis tuleb nähtavale võõrkeelne tõlge.
Tõlketeksti uuemad osad on lühikest aega esile tõstetud, et vaataja lisandusi kergemini märkaks. Selline kujundus lähtub tõsiasjast, et sisendkõne töötlemisel muutub tekst pidevalt. Ent tõlgitud tekst püsib ekraanil stabiilne – kui kõik ekraanil vilguks või ümber paikneks, oleks teksti raske lugeda.
Suure ekraani kõrval saab tõlget jagada ka väiksematesse seadmetesse – sündmuste korraldajail on võimalik avada tõlkevaade ning seda auditooriumile lingi või QR-koodi kaudu jagada. Samuti saab tõlget kasutada videoprojektsioonis ning kuvada seda näiteks OBS Studio kaudu otseülekande subtiitritena.
Süsteemi täpsusest
Kõnetuvastus ja masintõlge pole eksimatud. Kõige rohkem eksib süsteem nimede ja haruldaste terminite vahendamisel. Samuti võib tõlge olla kohati kohmakas, kaotada midagi lähtekõne stiilist – mudel pole poeetikas veel kõige filigraansem. Sellest hoolimata on katsed näidanud, et süsteem suudab edastada arusaadavat tõlget, eriti eestikeelse kõne vahendamisel ingliskeelseks tekstiks.
On huvitav, et eestikeelses kõnes – eriti kui kõneakt käsitleb tehnilist sisu – kasutatakse palju ingliskeelseid sõnu ja väljendeid. Süsteem selles suurt probleemi ei näe, sest oleme lisanud eestikeelsele treeningmaterjalile umbes 10% jagu ingliskeelset kõnet, et mudel selliseid kõneolukordi paremini tuvastaks. Kokkuvõttes jääb sünkroontõlge täpsuse poolest lausekaupa tõlkimisele küll pisut alla, ent vahe pole otsustavalt suur.
Kõnetuvastus ja masintõlge pole eksimatud.
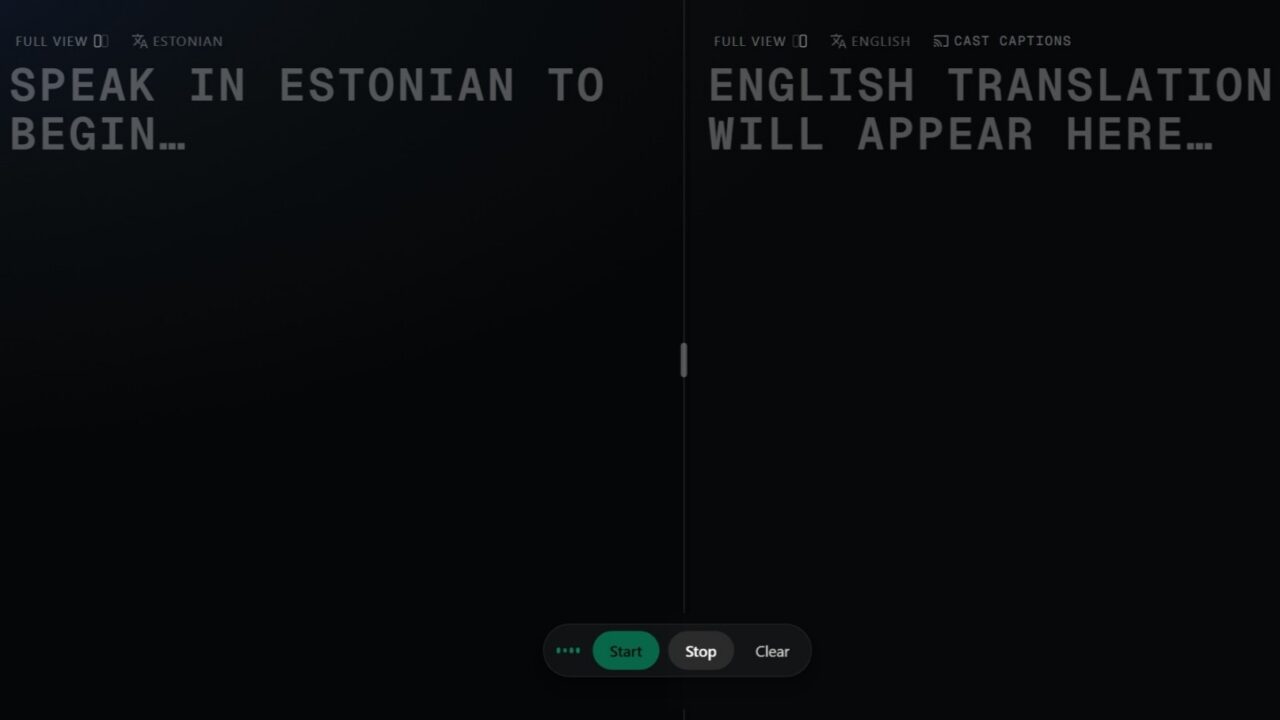
TalTechi kõnetõlkesüsteemi kasutajaliides kuvab eestikeelse kõnetuvastuse ja ingliskeelse tõlke kõrvuti, võimaldades kõnet jälgida peaaegu reaalajas.
Kuhu edasi?
Kõnetõlkesüsteem on loodud praktiliseks kasutamiseks, samuti on kavas seda jätkuvalt arendada ja täiustada. Mudelit saab kohandada erinevatele keelesuundadele ning kasutada eri tüüpi sündmustel.
Tulevikus muutuvad kõnetuvastus täpsemaks ja tõlkemudel ladusamaks, samuti saab arendada kasutajaliidest ning parandada sedakaudu tõlke loetavust nii suurel ekraanil, mobiiltelefonis kui ka videosubtiitrites. Lisaks on kavas arendada kõneväljundit, mis võimaldab sünteesida lähtekeelset vestlust võõrkeelseks, kõnelejale sarnast sünteeshäält kasutavaks kõneks.
Laiemas plaanis on aga meie töö näidanud, et eesti keele suguse väikse keele jaoks on edukalt võimalik luua kaasaegseid keeletehnoloogilisi ja praktilise potentsiaaliga lahendusi. Tehnoloogia suudab kõnetuvastuse, masintõlke ja kasutajasõbraliku veebirakenduse koosmõjus toetada vahetuid suhtlusolukordi. Eestikeelsete kõnelejate jaoks tähendab see aga võimalust jääda truuks emakeelele, s.t kasutada seda ka juhul, kui kuulajaskond on kas suures osas või suisa täielikult rahvusvaheline.
Eesti keele suguse väikse keele jaoks on edukalt võimalik luua kaasaegseid keeletehnoloogilisi ja praktilise potentsiaaliga lahendusi.
Süsteemi loomist toetab Eesti keeletehnoloogia riiklik programm 2018-2027 ning Keeleandmete Teadustaristu. Mudeleid treeniti TalTechi HPC-s ning LUMI superarvutis.


